本帖最后由 进击的鹏飞 于 2024-4-16 22:44 编辑
打开 Discord ,点击页面下方的 “给#常规 发消息”, 输入英文字符 “/” ,(不包含双引号) 输入框上方自动弹出如下菜单
这里所示的菜单项目,实际上是你可以对 Midjourney 机器人作出的指令,例如第一个“/imagine prompt” ,就是使用 Midjourney 机器人 创建图像的指令。又如第四个 “/settings”,就是要求Midjourney 机器人显示设置选项的指令。
而第三个指令看似与第一个指令一样,实际上,第三个是使用 niji journey 机器人创建图像的指令。niji journey 机器人是专门用于生成动画图像的,Midjourney 机器人则什么图像都能生成,包括动画图像,两者优劣见仁见智,需要不断尝试。
点击第一个,“/imagine prompt” 指令。
输入框里的 “给#常规 发消息” 变成了 “/imagine prompt” ,有一个方框专门框柱 prompt,并且后面可以输入内容。
这里的意思是:“你用于生成图像的咒语是什么?”
咒语,又叫提示词,用来形容你心目中想AI生成什么样的图像,它有什么人物?有什么背景?采用什么风格?有什么视觉效果?这些都是你需要通过提示词描述出来的。 目前 Midjourney 不接受中文提示词,你必须使用翻译软件,或ChatGPT等生成式AI工具,将你的描述翻译成英文。
我们尝试在 prompt 后面输入以下一段提示词: A lively girl happily dancing on the grass,rich colors, rich textures, --ar 9:16 (一个活泼的女孩在一片草地上快乐地跳舞,丰富的色彩,丰富的质感)
最后的“--ar 9:16” 决定了生成出来的图像的比例为9:16,这个值也可以是16:9 、4:3等等。 我们按回车,看看 Midjourney 生成出什么图像。
Midjourney 以缩略图的形式生成了4张图片,图片下方的U1、U2、U3、U4,分别表示放大第一张、第二张、第三张、第四张图片,V1、V2、V3、V4分别表示,按照第一张、第二张、第三张、第四张图片的风格,再生成4张图片。U4右边的按钮,表示重新生成4张新图片。
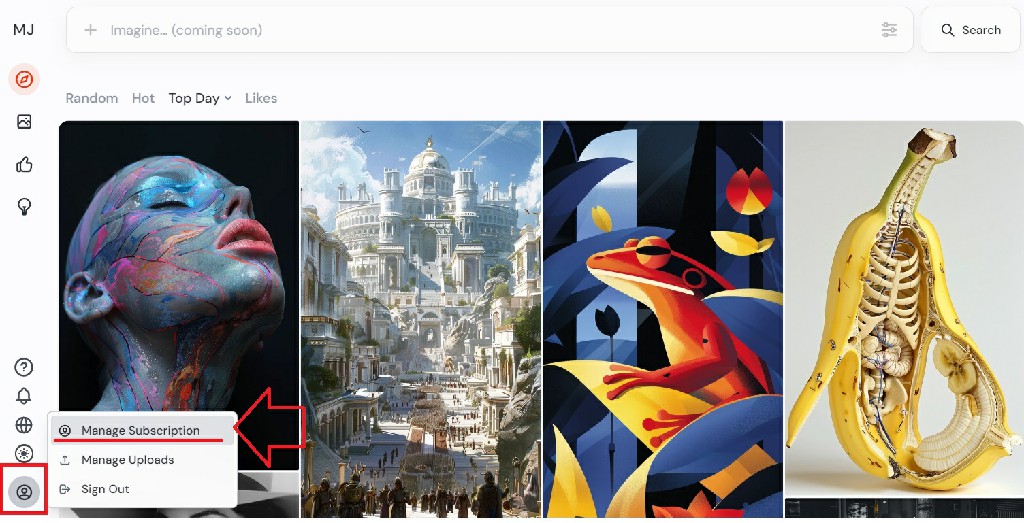
如果 Midjourney 弹出错误提示,可能说明你没有付费订阅,你需要转至Midjourney 官网,点击右下角的登录,登录后点击左下角头像按钮,选择“Manage Subscription”,在弹出来的页面里购买套餐,10美元可以在一个月内使用3.3小时,30美元可以在一个月内使用15小时。
言归正传,上图可以见到,Midjourney 生成出来的 4 张图片,都是偏向于水彩画或类似的风格,在这里我都不喜欢,我选择重新输入提示词。
点击 “给#常规 发消息”,选择 “/imagine prompt” 指令
这次我们在提示词里添加一个风格: A lively girl happily dancing on the grass,rich colors, rich textures, Miyazaki style, --ar 9:16 (一个活泼的女孩在一片草地上快乐地跳舞,丰富的色彩,丰富的质感,宫崎骏风格)
我在原来的提示词后面加多了一句“宫崎骏风格”,希望Midjourney 生成出不一样的图片,我们按回车,再看看Midjourney 这次生成的结果:
可以见到 Midjourney 生成出来的风格开始有点改变,特别是第二张,天空的云确实有点像宫崎骏笔下的风格,但是我对于第一、三、四张还是不满意,而且经过两次生图之后,我发觉如果背景有一片海会更加好看
我们重新输入提示词,点击 “给#常规 发消息”,选择 “/imagine prompt” 指令
我们描述一下想要的背景,要有海,而且我觉得“宫崎骏风格”未能使 Midjourney 准确掌握我想要的效果,这次我换成“吉卜力风格”看看会如何。
所以这次我们输入: A lively girl happily dancing on the grass,the background is a sea and a clear sky, rich colors, rich textures, ghiblistyle, --ar 9:16 (一个活泼的女孩在一片草地上快乐地跳舞,背景是海和晴朗的天空,丰富的色彩,丰富的质感,吉卜力风格)
按回车,等待 Midjourney 生成:
增加了对背景的描述后,Midjourney 生成了4张拥有海和晴空背景的图像,而且风格上也更接近吉卜力动画的画风了。在这4张图像中,我对第2张感到最满意。 点击U2,将第2张图像放大。
Midjourney 单独显示了第2张图片,如果没有其他要求,这时我们就可以将这个图像下载到电脑,算是完成了一次作图, 同时我们留意到,使用U2指令放大第2张图后,下方的指令也出现了变化。
Upscale(Subtle),表示放大图片清晰度,放大后的图像与原图很相似 Upscale(Creative),表示放大图片清晰度,放大后的图像与原图可能有所不同 Vary(Subtle),表示对这个图片进行比较弱的变体 Vary(Strong),表示对这个图片进行比较强的变体 Vary(Region),弹出一个窗口,让你框选图片的特定部分,通过新的提示词进行微调 Zoom Out 2x ,表示对场景进行2倍缩放 Zoom Out 1.5x,表示对场景进行1.5倍缩放 Custom Zoom,用来让你自定义缩放比例 Make Square,将这个图片的比例变成正方形 上下左右箭头,表示向上、下、左、右填充图片内容
AI 生图有一定的随机性,想要生成出自己心目中的图片,往往需要像上述案例一样多次尝试,并且你要作出一个心理准备就是,可能AI最终都生成不到令你满意的图片。
现在你已经可以根据自己的想法,反复尝试不同提示词,观察AI生成出来的效果。然后加入不同的参数,观察我前文提到的“放大清晰度、变体、场景缩放”等实际会产生什么效果。
最后,如果你在提示词中形容小乔的形象,你会发现最终是怎么都生成不了小乔的。因为生成小乔需要垫图,这则回帖只是告诉了你 Midjourney 生图的基本操作,建议你先消化这一部分的内容,自己实践一下用不同提示词生成不同图片,有不明白的地方可以问我,力所能及范围内我会尽力解答你,熟练后想进一步搞埋垫图,再回帖告诉我。(其实不难的)
打字不易,如果你觉得我的解答对你有帮助,可以以自愿为原则打赏雪点。
| 
 [复制链接]
[复制链接]








 雷达卡
雷达卡

 显身卡
显身卡